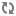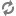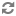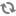|
Principe |
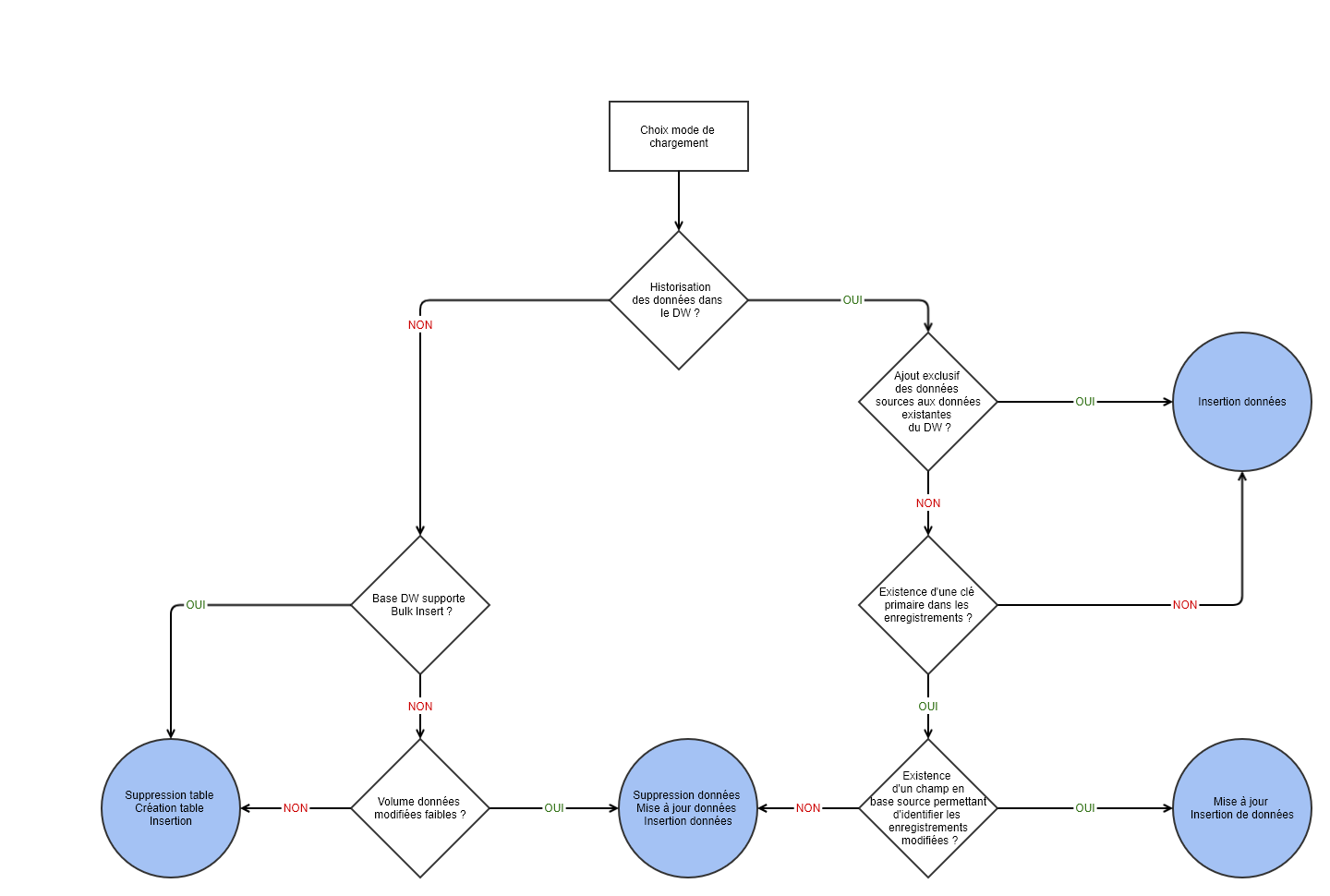
Le mode de chargement permet de spécifier la manière dont la table de l'entrepôt est alimentée, et d'optimiser les temps d'ETL |
|
Accès |
Click droit sur le modèle -> "Propriétés d'un modèle" -> onglet "Chargement" -> propriété "Mode de chargement" |
|
Valeurs |
Choix du mode :
|
Tableau 14.1. Disponibilité des modes de chargement
|
Mode de chargement |
Destination | |
|---|---|---|
|
Datawarehouse |
Fichier CSV | |
|
Suppression table / Création table / Insertion données |
 |
|
|
Insertion données |
|
|
|
Mise à jour données / Insertion données |
|
 |
|
Suppression données / Mise à jour données / Insertion données |
|
|
|
Table partagée (multi-sources) |
|
|
Il s'agit du mode d'ETL sélectionné par défaut.
Fonctionnement (Base de données autorisant le renommage de table)
Lors de l'ETL, une table temporaire est créée puis alimentée. Si l'ETL se déroule sans erreur la table originale est supprimée, puis la table temporaire est renommée pour devenir la table officielle. Sinon la table temporaire est supprimée et la table originale préservée.
Ce système permet d'éviter de perdre la table d'avant ETL si ce dernier se termine avec des erreurs.
- Datawarehouse : CREATE TABLE "temporaire"
- Source : SELECT
- Datawarehouse : INSERT in TABLE "temporaire"
- Datawarehouse : DROP TABLE "origine"
- Datawarehouse : RENAME TABLE "temporaire"
Fonctionnement (Base de données n'autorisant pas le renommage de table)
Lors de l'ETL, la table est supprimée, recréée puis alimentée.
- Datawarehouse : DROP TABLE
- Datawarehouse : CREATE TABLE
- Source : SELECT
- Datawarehouse : INSERT
Attention
Firebird et Interbase (et leurs pendant ODBC) ne gèrent pas le renommage de tables.
Ce mode d'ETL insère les données sources à la suite des données existantes dans l'entrepôt. Il peut être utilisé pour gérer de l'historisation d'informations.
Il est possible de définir un critère de suppression des enregistrements qui s'applique aux données existant dans l'entrepôt.
Ce mode ne permet pas de gérer la suppression dans l’entrepôt des données qui ne sont plus présentes dans la source de données.
Fonctionnement
- Datawarehouse : ALTER TABLE (Si la structure de la table ne correspond pas au paramétrage des champs destination)
- Datawarehouse : DELETE WHERE "critère de suppression"
- Source : SELECT
- Datawarehouse : INSERT

Important
Le critère de suppression n'est pas utilisé lors de l'insertion des données sources. Pour filtrer les données à insérer, il faut passer par les filtres du modèle
Ce mode d'ETL permet de ne recharger dans l'entrepôt que les données susceptibles d'avoir évoluées.
Pour identifier ces enregistrements dans les données source et dans l'entrepôt, MyReport Data demande un critère de sélection et une clé primaire :
- MyReport requête la base source pour insérer les données correspondant au "critère de sélection" dans une table temporaire
- MyReport supprime de l'entrepôt les données correspondant aux valeurs des clés primaires présentes dans la table temporaire
- MyReport insère l'intégralité de la table temporaire dans l'entrepôt de données.
Ce mode ne permet pas de gérer la suppression dans l’entrepôt des données qui ne sont plus présentes dans la source de données.
Fonctionnement
- Source : SELECT ... WHERE "critère de sélection"
Table Temporaire : INSERT * WHERE "critère de sélection"
- Si la connexion datawarehouse autorise le Bulk Copy, on insère les données dans le Datawarehouse via ce mode.
- Datawarehouse : DELETE FROM Table Temporaire WHERE clé
- Datawarehouse : INSERT * FROM Table Temporaire

Tableau 14.3. Exemple :
|
Contexte : Mon logiciel de facturation contient les factures et leur date de dernière modification. Je souhaite n'intégrer dans mon entrepôt que les factures émises depuis mon dernier ETL réussi. Critère de sélection : [Date modification] >= ExtraitDate(DateETLOK) Date du jour lors du traitement des données : 10/09/2018 Date de dernier ETL réussi : 09/09/2018 Clé primaire : Id facture |
|
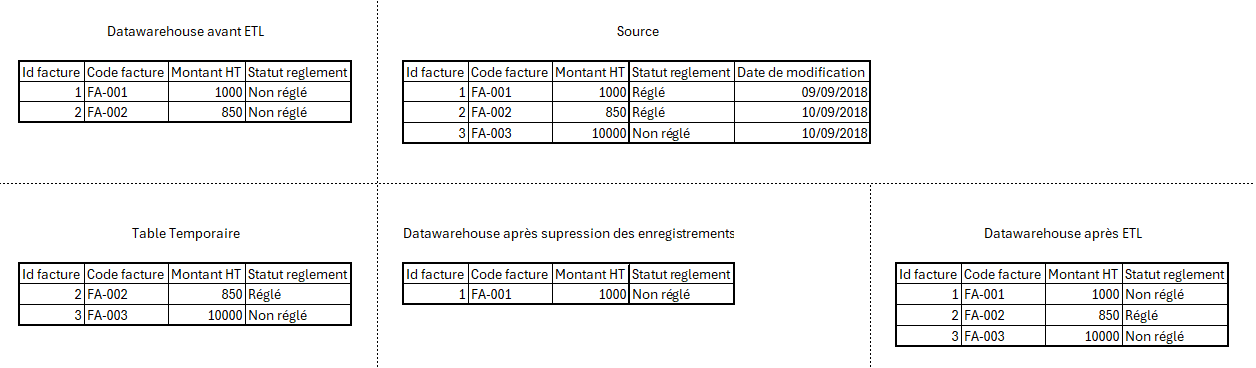
Ce mode permet de synchroniser les données d'un sous ensemble de l'entrepôt de données, via un critère de mise à jour facultatif.
Ce critère de mise à jour facultatif s'applique pour récupérer les enregistrements, triés selon la valeur de la clé primaire, existants dans la base source et dans l'entrepôt de donnée. Il ne peut être défini que sur un champ non transformé ou transformé SQL.
Ces enregistrements sont ensuite comparés un à un afin de déterminer l'action à mener (ajout, modification ou suppression)
Ce mode de chargement permet de supprimer de l'entrepôt les données qui n'existent plus dans les bases source.
Fonctionnement
- Source : SELECT champs WHERE "critère de mise à jour" ORDER BY "clé"
- Datawarehouse : SELECT champs WHERE "critère de mise à jour" ORDER BY "clé"
Parcours des listes Source et Datawarehouse sur le champ "clé"
Clé source > Clé datawarehouse : L'enregistrement Datawarehouse n'existe plus dans la source.
- Suppression de l'enregistrement du Datawarehouse : DELETE FROM... WHERE clé = Valeur_Clé_datawarehouse
- Passage à la clé suivante coté Datawarehouse
Clé source < Clé datawarehouse : L'enregistrement présent en source n'existe pas dans le Datawarehouse.
- Ajout de l'enregistrement au Datawarehouse : INSERT...
- Passage à la clé suivante coté Source
Clé source = Clé datawarehouse : comparaison et mise à jour de l'enregistrement dans le datawarehouse
- Comparaison des valeurs de l'enregistrement source et Datawarehouse
- Si différence, Mise à jour de l’enregistrement du Datawarehouse : UPDATE SET... WHERE Valeur_Clé_datawarehouse = Valeur_Clé_Source
- Passages aux clés suivantes (source et Datawarehouse)
Avertissement
Le tri des enregistrements selon leur clé primaire exploite les paramètres "Tri binaire délimiteur champ gauche" et "Tri binaire délimiteur champ droit" définis dans la des connexions source et de l’entrepôt de données, si le champ est de type texte. Il est impératif que les 2 bases renvoient les enregistrements triés dans le même ordre pour que ce mode d'ETL fonctionne.
Tableau 14.4. Exemple :
Important
Cette fonctionnalité est mise à disposition en tant que fonctionnalité Beta. Elle fonctionne, mais des travaux d'amélioration de l'UX/UI sont en-cours (configuration du mode table partagée, avertissements lorsqu'on modifie la structure d'un modèle en table partagée pouvant générer des erreurs d'ETLs, etc...).
Le mode Table partagée (multi-sources) permet à plusieurs modèles d'alimenter une même table du Datawarehouse au sein d'un même projet.
Cette configuration centralise le nom de la table SQL et l'option de configuration du nombre de lignes par lot. Plusieurs modèles peuvent être rattachés à la même configuration et alimentent alors la même table de destination.
L'utilisateur peut choisir une configuration existante ou en créer une nouvelle. Une indication textuelle liste les autres modèles rattachés à la même table.
Fonctionnement
Lors du lancement d'un ETL, si l'utilisateur sélectionne un modèle rattaché à une table partagée, tous les autres modèles partageant la même table sont automatiquement inclus dans l'exécution. Tous les modèles d'une même table partagée sont automatiquement promus au rang le plus élevé du groupe, afin qu'ils s'exécutent ensemble au bon moment dans la séquence ETL.
Important
Le mode "Table partagée" charge les données en mode "Suppression Table / Création Table / Insertion Données".
L'alimentation est coordonnée :
- La table est créée.
- Puis chaque modèle y insère ses données (en parallèle ou séquentiellement selon le paramétrage).
- Et enfin les clés primaires et index sont recréés.
Points d'attention
Aucune validation de la structure des modèles d'une même table partagée :
- Si la modélisation n'est pas identique entre les différents membre d'une même table partagée, une erreur pourra être levée l'exécution de l'ETL. Les écarts de modélisation incluent, bien entendu, le nombre de champs, mais aussi les types de champs, ainsi que leurs tailles.
- Les écarts de modélisation incluent le nombre de champs, mais aussi les types de champs, ainsi que leurs tailles.
Jointure entre modèles d'une même table partagée :
- Si deux modèles rattachés à la même table partagée sont inclus dans une même modélisation et qu'une jointure est faite entre eux, les données sont dupliquées en puissance N (N = nombre de jointures). Il est déconseillé d'avoir cette configuration.