Si vous avez positionné le paramètre Chargement à OUI ou à AUTOMATIQUE, vous pouvez préciser la manière dont seront insérées les données dans la table résultante.
Quatre modes d’insertion sont possibles dans MyReport Data :
« Suppression table / Création table / Insertion données »,
« Insertion données »,
« Mise à jour données / Insertion données »,
« Suppression données / Mise à jour données / Insertion données ».
Lorsque le mode « Suppression table / Création table / Insertion données » est sélectionné, la table correspondant au modèle est supprimée au début de chaque ETL, puis recréée avant l’insertion de toutes les données correspondant à votre paramétrage (champs destination, filtres …).
Note
Il s’agit du mode de chargement par défaut. En rechargeant l’intégralité des données, il garantit leur intégrité. En contrepartie, le temps de chargement sera plus long.
Lorsque le mode « Insertion données » est sélectionné, à chaque ETL, les données sont insérées à la suite des données précédentes.
Attention
Avec ce mode, il n’y a pas de contrôle de redondance : une même ligne déjà présente dans la table cible sera insérée si elle est présente dans les données sources lors de l’ETL suivant. Il faut donc veillez à faire attention avant de positionner une clé primaire dans le modèle utilisant ce mode de chargement. Une solution sera alors de créer une clé concaténée qui garantit l’unicité de chaque enregistrement.
Ce mode s’accommode d’un changement de structure de la table (ajout d’une colonne, suppression d’une colonne, modification du type d’une colonne).
Si une colonne est ajoutée : ses données seront vides jusqu’au premier ETL sur le modèle avec cette nouvelle colonne.
Si une colonne est supprimée : les données « historique » de cette colonne sont perdues.
Si le type d’une colonne est modifié dans MyReport Data : le changement est répercuté sur la table de destination.
Ce mode permet de ne charger que les données susceptibles d’avoir évolué. Pour cela vous allez spécifier un filtre (le plus souvent sur une date) permettant de ne mettre à jour que les données correspondantes.
Exemple : seules les écritures comptables de l’exercice comptable peuvent être modifiées. Si vous souhaitez disposer d’un historique de 3 ans dans l’entrepôt de données, il serait plus intéressant de ne charger, à chaque ETL, que les écritures de l’exercice en cours plutôt que tout l’historique.
Avant de pouvoir utiliser le mode « Suppression de ligne/Insertion », vous devez définir une clé primaire sur votre modèle. Lorsque la clé primaire sera définie, vous pourrez spécifier un filtre correspondant au critère de « mise à jour données / insertion données ».
Les données correspondantes à votre filtre seront supprimées de la table de l’entrepôt de donnée puis les données sources correspondant à ce même filtre seront extraites puis insérées dans la table de l’entrepôt.
Vous pouvez personnaliser le critère de filtre dans les propriétés du modèle, en cliquant sur le bouton MODIFIER.

La syntaxe sera alors la suivante : [MonChamp] >= Formule, où « Formule » est une formule écrite avec la syntaxe utilisée lors de la création de champs calculés dans MyReport Data.
Exemple : pour reprendre l’exemple précédent, vous pouvez spécifier, dans le filtre, la date de clôture de l’exercice, et la modifier régulièrement :
[Date facture] > 30/04/2021
Il serait plus pertinent de rendre variable ce filtre de sorte qu’il devienne générique. Si l’exercice N-1 est clôturé en Avril (ex : l’exercice comptable 2021 est clôturé fin avril 2022), il faudra alors recharger jusqu’à fin avril les données de l’année N et de l’année N-1, alors que le chargement de l’année 2022 suffira à partir du mois de mai.
Dans ce cas, la syntaxe sera donc :
[Date facture] >= Si ( mois(Aujourdhui) <=4 ; EncodeDate ( Annee ( Aujourdhui )-1 ; 1 ; 1 ) ; EncodeDate ( Annee ( Aujourdhui ) ; 1 ; 1 ) )
Lors du premier ETL sur ce modèle, l’ensemble des données sera rechargé dans l’entrepôt pour constituer l’historique puis le filtre du mode de chargement sera pris en compte lors des ETL suivants pour ne prendre en compte que les données susceptibles d’avoir évolué.
Afin de s’assurer que toutes les données souhaitées soient bien dans l’entrepôt de données, il est possible de spécifier un jour de la semaine où l’ETL réinitialisera totalement la table : toutes les données seront chargées et pas uniquement les données correspondant au filtre du mode de chargement.

Ce mode permet aussi d’exploiter des dates présentes dans vos données sources.
Il n’est pas rare de rencontrer des dates de dernière modification attachées aux enregistrements.
Il sera alors possible d’utiliser cette date pour ne charger que les données qui ont évoluées depuis le dernier chargement, limitant ainsi le nombre de lignes à traiter.

Avec le filtre précédent :
Le premier ETL chargera l’ensemble des données de la table source
Dans les chargements suivants, seules les lignes ayant une date de modification plus récente que le dernier ETL seront chargées dans la table de l’entrepôt.
Attention
Certaines actions qui impactent la structure de la table nécessiteront une réinitialisation de la table. Parmi celles-ci, la modification/ajout de la clé primaire, la suppression d’un champ, le renommage d’un champ en base, l’ajout/la suppression d’un index. Un message d’avertissement vous préviendra de cela avant validation.
Comme le mode précédent, ce mode permet de ne mettre à jour qu’une partie des données.
Sur votre modèle, vous devez définir un champ unique qui sera votre clé primaire.
Lors de l’ETL, MyReport effectue la requête sur les données sources du modèle et sur la table de l'entrepôt de données, en triant les données selon cette clé primaire.
Ensuite, MyReport Data parcourt simultanément et compare les deux listes d’enregistrements :
Si l'enregistrement existe uniquement dans la source :
Les données source sont ajoutées à l'entrepôt de données
MyReport passe ensuite à l’enregistrement « source » suivant.
Si l'enregistrement existe uniquement dans l'entrepôt :
Les données de l'entrepôt sont supprimées de l'entrepôt de données
MyReport passe ensuite à l’enregistrement "DataWarehouse" suivant.
Si l'enregistrement existe des deux côtés :
Les données sont comparées, l'enregistrement de l'entrepôt est mis à jour si nécessaire
MyReport passe ensuite aux enregistrements "Source" et "Datawarehouse" suivants
Note
Information : ce mode de chargement permet un gain de temps lors des ETL lorsqu’il a peu de données modifiées.
Attention
Dans le cas d’une clé primaire alphanumérique, le résultat du tri peut être différent entre 2 moteurs de base de données, mais aussi pour une même base si la page de codes* des bases est différente.
Page de codes : standard qui vise à donner un numéro unique à chaque caractère d'une langue.
Pourquoi ?
Certaines bases de données prennent en compte la langue, d'autre pas, certains ne distinguent pas les majuscules et les minuscules, d'autres pas, ...
Le fonctionnement du mode " Suppression données / Mise à jour données / Insertion données" est sensible au résultat du tri. Lorsque ce dernier n'est pas identique entre les données source et celles de l'entrepôt, le mode " Suppression données / Mise à jour données / Insertion données " n'aboutira pas.
Pour pallier cette difficulté, MyReport Data utilise le tri binaire, le seul tri permettant une comparaison systématique, lorsque la clé primaire contient un champ de type Texte.
|
Le tri binaire est paramétrable de la manière suivante pour ces quelques bases :
|
En conséquence, la syntaxe permettant de mettre en œuvre le tri primaire sur un champ de type Texte est définie dans l’écran SYNTAXE SQL rattaché aux bases de données ci-dessus.
Exemple pour SQL Server :
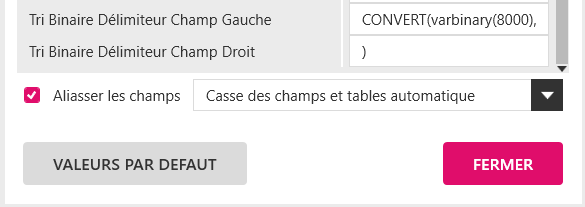
Pour les autres bases de données, il sera nécessaire de définir la syntaxe du tri binaire.